
My name is Hui Wang, and I am currently a fourth-year direct Ph.D. student at the College of Computer Science, Nankai University, specializing in Computer Science and Technology. I began my Ph.D. journey in 2022, joining the university’s program under the supervision of Professor Yong Qin.
Currently, I am interning at Tencent Hunyuan, where I am gaining practical experience in my research area. My research focuses on speech synthesis, speech quality assessment, and related technologies, and I have been actively involved in various projects in this field.
If you are interested in academic collaboration or internship opportunities, please feel free to reach out to me via email.
🔥 News
- 2025.10: 🎉 We have released a series of evaluation models, including AuditEval, AudioEval, and SpeechEval.
- 2025.09: 🎉 Our Elderly Conversation Dataset SeniorTalk is accepted by NeurIPS 2025.
📝 Publications
🎙 Speech Synthesis
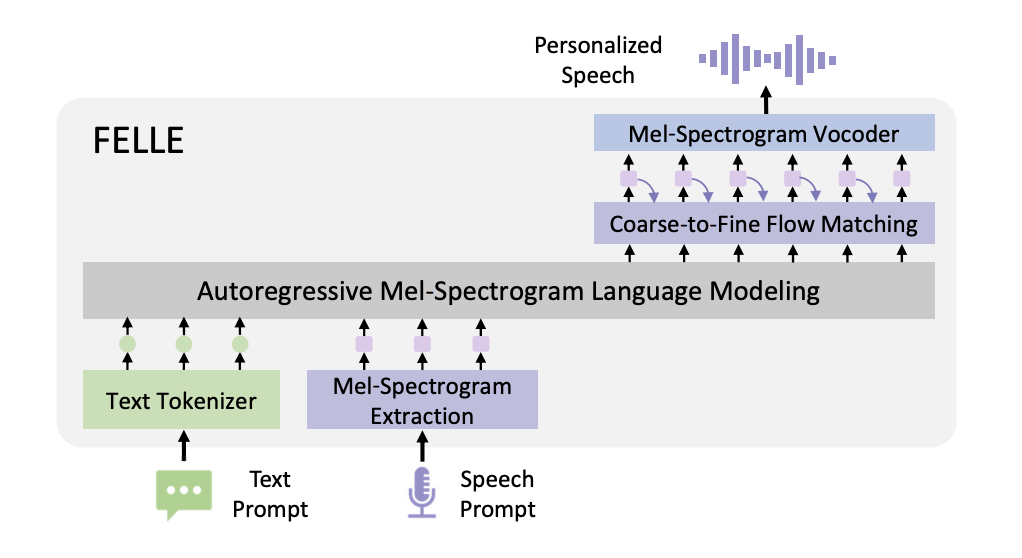
FELLE: Autoregressive Speech Synthesis with Token-Wise Coarse-to-Fine Flow Matching
Hui Wang, Shujie Liu, Lingwei Meng, Jinyu Li, Yifan Yang, Shiwan Zhao, Haiyang Sun, Yanqing Liu, Haoqin Sun, Jiaming Zhou, Yan Lu, Yong Qin
-
Signal Process Letter StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling, Hui Wang, Yifan Yang, Shujie Liu, Jinyu Li, Lingwei Meng, Yanqing Liu, Jiaming Zhou, Haoqin Sun, Yan Lu, Yong Qin
-
Arxiv Towards Responsible Evaluation for Text-to-Speech, Yifan Yang*, Hui Wang*, Bing Han, Shujie Liu, Jinyu Li, Yong Qin, Xie Chen
🎤 Speech & Audio & Music Quality Assessment
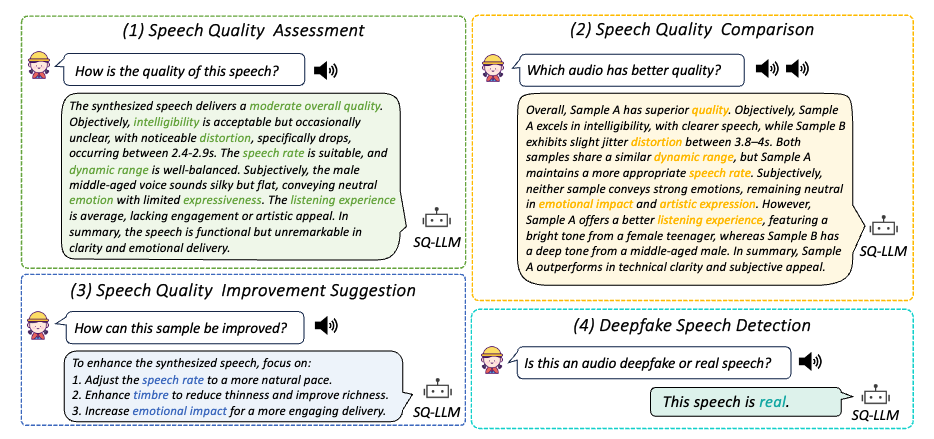
SpeechLLM-as-Judges: Towards General and Interpretable Speech Quality Evaluation,
Hui Wang, Jinghua Zhao, Yifan Yang, Shujie Liu, Junyang Chen, Yanzhe Zhang, Shiwan Zhao, Jinyu Li, Jiaming Zhou, Haoqin Sun, Yan Lu, Yong Qin
-
Arxiv AudioEval: Automatic Dual-Perspective and Multi-Dimensional Evaluation of Text-to-Audio-Generation, Hui Wang, Jinghua Zhao, Cheng Liu, Yuhang Jia, Haoqin Sun, Jiaming Zhou, Yong Qin
-
AAAI 2026 TTA-bench: A comprehensive benchmark for evaluating text-to-audio models, Hui Wang*, Cheng Liu*, Junyang Chen, Haoze Liu, Yuhang Jia, Shiwan Zhao, Jiaming Zhou, Haoqin Sun, Hui Bu, Yong Qin
-
Arxiv Towards Automatic Evaluation and High-Quality Pseudo-Parallel Dataset Construction for Audio Editing: A Human-in-the-Loop Method, Yuhang Jia*, Hui Wang*, Xin Nie, Yujie Guo, Lianru Gao, Yong Qin
-
IEEE TASLP RAMP+: Retrieval-Augmented MOS Prediction With Prior Knowledge Integration,Hui Wang, Shiwan Zhao, Xiguang Zheng, Jiaming Zhou, Xuechen Wang, Yong Qin
-
ICASSP 2025 MusicEval: A Generative Music Dataset with Expert Ratings for Automatic Text-to-Music Evaluation, Cheng Liu*, Hui Wang*, Jinghua Zhao, Shiwan Zhao, Hui Bu, Xin Xu, Jiaming Zhou, Haoqin Sun, Yong Qin
-
Interspeech 2024 Uncertainty-Aware Mean Opinion Score Prediction, Hui Wang, Shiwan Zhao, Jiaming Zhou, Xiguang Zheng, Haoqin Sun, Xuechen Wang, Yong Qin
-
Interspeech 2023 RAMP: Retrieval-Augmented MOS Prediction via Confidence-based Dynamic Weighting, Hui Wang, Shiwan Zhao, Xiguang Zheng, Yong Qin
-
ICME 2023 Intermediate-Task Learning with Pretrained Model for Synthesized Speech MOS Prediction, Hui Wang, Xiguang Zheng, Yong Qin
🔍 Elderly Speech Analysis
-
NeurIPS 2025 SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors, Yang Chen*, Hui Wang*, Shiyao Wang, Junyang Chen, Jiabei He, Jiaming Zhou, Xi Yang, Yequan Wang, Yonghua Lin, Yong Qin
-
Arxiv WildElder: A Chinese Elderly Speech Dataset from the Wild with Fine-Grained Manual Annotations, Hui Wang*, Jiaming Zhou*, Jiabei He, Haoqin Sun, Yong Qin
🎖 Honors and Awards
- 2024 VoiceMOS 2024 Challenge First Place in Track 1; Two First Places and One Second Place in Track 3 🏆
- 2023 VoiceMOS 2023 Challenge Track 3 Third Place
📖 Educations
- 2018.09 - 2022.06, China University of Mining and Technology, XuZhou
- 2022.09 - Present, Nankai University, Tianjin
💻 Internships
- 2024.07 - 2025.07, Microsoft Research Asia, Beijing. Co-supervised by Dr. Shujie Liu and Dr. Jinyu Li
- 2025.08 - Present, Tencent Hunyuan, Beijing.